Weixian (Waylon) Li
Monday, August 8, 2022
Contrastive Learning Note
Related reading:
- The Beginner’s Guide to Contrastive Learning
- SimCSE: Simple Contrastive Learning of Sentence Embeddings
- A Simple Framework for Contrastive Learning of Visual Representations
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Background
Contrastive learning aims to learn effective representation by pulling semantically close neighbors together and pushing apart non-neighbors. Initially, contrastive learning was applied to computer vision tasks. As what it is shown in the figure below, we expect the model to learn the communities between two images that share the same label and the difference between a pair of images with different labels.
This idea is very similar to the way how humans learn from their experience. Humans can not only learn from positive signals but also from correcting the negative behaviours.

The crucial steps in contrastive learning are:
- Defining the measurement of distance
- Positive samples generation / selection
- Negative samples generation / selection
In usual cases, samples are encoded to the vector space and the Euclidean distance will be used to represent the distance between a pair of samples. Once we figure out the strategy to generate / select the positive and negative samples, we can define a triplet $(x, x^+, x^-)$ containing an anchor sample $x$, a positive sample $x^+$, and a negative sample $x^-$. The triplet loss can be represented as:
$$ L = max(0, ||x - x^{+}||^2 - ||x - x^{-}||^2 + m) $$
The triplet loss is widely used as the objective function for contrastive learning.
SimCSE: Contrastive Learning Framework for NLP
SimCSE consists of two version: unsupervised and supervised, shown in the figure below.
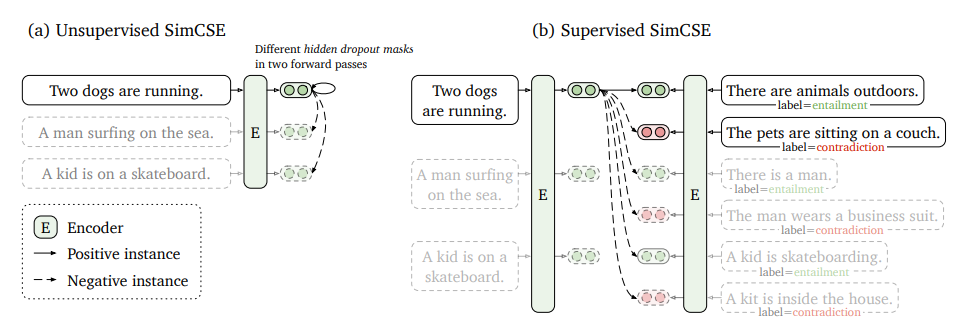
The unsupervised SimCSE predicts the input sentence itself from in-batch negatives, with different hidden dropout masks applied. Supervised SimCSE leverages the NLI datasets and takes the entailment (premise-hypothesis) pairs as positives, and contradiction pairs as well as other in-batch instances as negatives.
Assume a set of paired examples $\mathcal{D} = {(x_i, x_i^+)}_{i=1}^m$, where $x_i$ and $x_i^+$ are semantically related. Let $\mathbf{h}_i$ and $\mathbf{h}_i^+$ denote the representations of $x_i$ and $x_i^+$, the training objective for $(x_i, x_i^+)$ with a mini-batch of $N$ pair is:
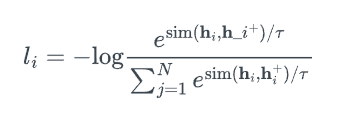
where $\tau$ is a temperature hyperparameter and $\textrm{sim} (\mathbf{h}_1, \mathbf{h}_2)$ is the cosine similarity.
Unsupervised SimCSE
Unsupervised SimCSE takes a sentence as input for twice to get two different embeddings. The reason why these two embeddings are not the same is, the dropout layer in the model will randomly set input units to 0 so that the output varies in each run of the model.
In each batch, the two different embeddings generated from the same sentence will be treated as the positive samples and the output of other sentences will be used as negative samples. The remaining thing is just to optimize the model parameters to make positive samples closer to each other and seperate the negative samples in the meantime.
Supervised SimCSE
In the labelled dataset, the only thing we need to do is to create a branch of triplet using the data we already have. The following idea is similar with unsupervised SimCSE once we get the positive samples and negative samples settled.
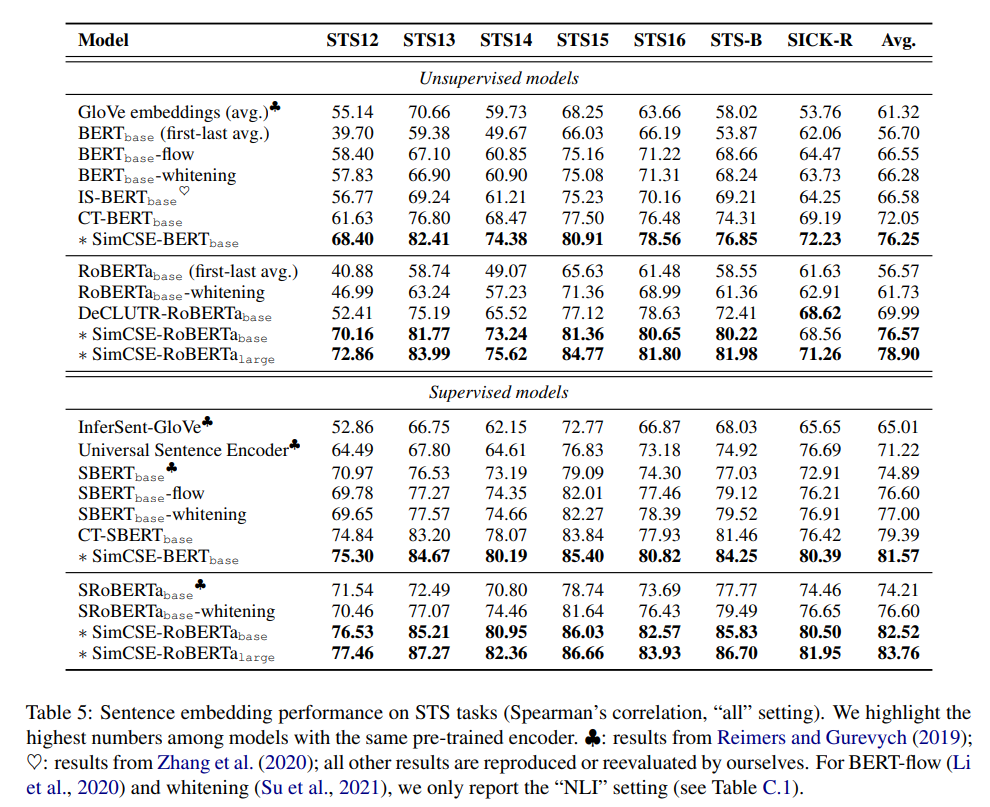
Result
The proposed SimCSE greatly improves state-of-the-art sentence embeddings on semantic textual similarity tasks.